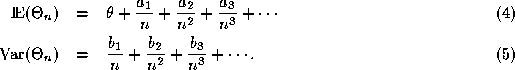Set the initial values N=30000, I=10. We make the conservative
choice of ![]() .
For every
.
For every ![]() define n(i)=100i and
define n(i)=100i and ![]() .
.
Formula (3) is required because under certain hypothesis (see, for example, Lehmann (1983)), the following asymptotic expansions hold:
If that is the case, one could carry on analyzing the regression model defined by:
where ![]() estimator of
estimator of ![]() ,
``sample mean'' over samples of
,
``sample mean'' over samples of ![]() of size M(i),
of size M(i),
![]() ,
, ![]() ,
,
![]() ,
, ![]() .
Here,
.
Here, ![]() represents any of the
represents any of the ![]() (100 in total).
(100 in total).
Now, since ![]() we have from
equation (5) that, for n(i) large:
we have from
equation (5) that, for n(i) large:
![]()
using equation (4).
Thus, ![]() .
Moreover, taking into account the simulation scheme, we might consider
that
.
Moreover, taking into account the simulation scheme, we might consider
that ![]() are independent (notice that, for each
are independent (notice that, for each
![]() the generation proceeds, instead of going back to the
beginning).
the generation proceeds, instead of going back to the
beginning).
We can then apply a regression analysis to the model (6)
considering the values ![]() as the observed values of
as the observed values of ![]() .
Then, for example using least squares estimators, we could
estimate the coefficients in (6) with
.
Then, for example using least squares estimators, we could
estimate the coefficients in (6) with
In order to assess the accuracy of the estimators in (7), the simulation could be carried on obtaining, say R, values like

Then, one could analyze the empirical distributions of
![]()
and, from this, we would obtain estimates of the accuracy of the
least squares estimators in model (6).
Remember that, in most of the situations, our main goal will be knowledge about ![]() ; but
; but ![]() is also interesting since it says
something about the asymptotic bias of the procedure.
is also interesting since it says
something about the asymptotic bias of the procedure.
Observe that, after performing those R replications we will have at
hand RM(i) outcomes of the random variable ![]() :
:
![]() .
This sample would allow us to study its empirical distribution.
We omit this last part in this work.
.
This sample would allow us to study its empirical distribution.
We omit this last part in this work.