Não-determinismo está no núcleo
das dificuldades que o experimento original de Adleman foi desenvolvido
para superar. A classe NP é definida como a classe dos problemas
algoritmos cujas soluções podem ser verificadas mas não
necessariamente eficientemente achadas. Do ponto de vista computacional,
implementar não-determinismo por um processo determinístico
é talvez a melhor contribuição de Adleman. Por outro
lado, não-determinismo é , supostamente, bem entendido no
contexto dos autômatos de estados finitos, uma vez que a construção
de subconjuntos produzem um equivalente determinístico para um autômato
não-determinístico dado. É aceitável que uma
melhor idéia sobre as dificuldades pode ser ganha tentando achar
meios de implementar não-determinismo diretamente em DNA.
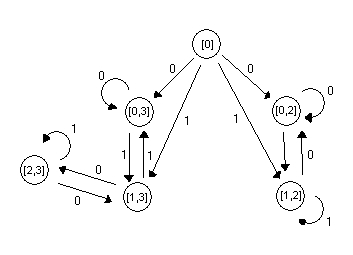
Um exemplo é mostrado abaixo, ele checa a
divisibilidade por 2 e por 3 numa string binária. Ele vai ser usado
durante a nossa implementação. Um fsm não-determinístico
faz computação em runs. Uma run é uma seqüência
de transições de estados válida de acordo com a tabela
de transição W . Isto é : cada q t e W (q t-1 , x
t ) , onde x : = x , x2 ... xm é a string de entrada
e q0 é o estado inicial. No geral há mais de uma run para
uma máquina não-determinística. A nfsm aceita a entrada
se houver pelo menos uma run que seja legal e chegue com sucesso no estado
final. Alternativamente, um nfsm pode ser visto como um fsm ordinário
determinístico com a capacidade de fazer copias dele mesmo quando
faz um movimento não determinístico, e cada uma das cópias
correspondendo a um dos movimentos. Esta última visão serve
bem para a implementação de DNA devido ao grande paralelismo
na computação DNA.
A saliência da cadeia simples é nomeada
depois dos símbolos de entrada correspondentes. A cadeia dupla é
responsável pelos símbolos de entrada ( GAG é código
do nucleotídeo para 0, GCA para o 1 ; há uma molécula
inicial especial ) , e pela saliência no código onde é
informado o estado atual.
Especificamente, os estados nas fsm são codificados
por seqüências de nucleotídeos contendo bases discriminativas
dadas por:
estado [0] : atat
estado [0,3] : ttat
estado [1,3] : gctg
estado [2,3] : ctca
estado [0,2] : tatt
estado [1,2] : gtcg
A molécula inicial é :
GGGGAGATCatatCTTAA
CCCCTCTAG
Para uma boa simulação da transição, cada um dos estados precisa ter tantos anéis quantas forem as transições neles necessárias. A codificação é similar ao caso determinístico. A principal diferença é que como há mais de um caso saindo de um estado com a mesma escolha ( 0 ou 1 ) os dois casos serão apresentados.
Obs. : A cadeia de DNA é composta de duas "faixas" onde uma é o simétrico da outra trocando: A por T , G por C e vice-versa.
Exemplo :
Legenda:
- Parte do encaixe :
Onde a molécula
irá se encaixar com a seqüência. Ele deve ser simétrico
à parte de encaixe da seqüência.
- Próximo estado :
Próximo estado do
autômato.
- Caminho escolhido ( 0 ou 1 ) :
Bit que será lido
pelo autômato.
- Enzima de restrição SmaI :
As enzimas de restrição
têm como função básica fazer a ligação
e a separação ( se for o caso ) entre duas moléculas.
Esta é colocada
aqui para o encaixe entre as moléculas poder ser realizado.
- Enzima de restrição EcoRI :
Esta é colocada
para o caso de se querer fazer uma nova ligação. A parte
à direita desta enzima é desprezada e ela está pronta
para o próximo encaixe.
- Anel :
É uma cadeia dupla
de DNA com um oligo não hibridizado na forma de um loop. Os tamanhos
do loop e do nucleotídeo no anel vão variar de acordo com
o tamanho do fsm que está sendo simulado.
- Esta parte é importante :
Pois na molécula
de DNA é imprescindível que haja simetrização
entre suas faixas. Esta parte é escolhida sendo igual à
parte no final do loop. No [0]0 , ela ( ATC ) é igual à do
final do loop ( atC ). No momento que desprezamos a parte à
direita do EcoRI para fazer a próxima ligação, a parte
que restou à direita , de baixo , ( TAG ) deslizará para
encaixar com a parte à esquerda ( ...CTC ) . Então
o ( TAG ) passará a ser o simétrico do ( ATC ) e não
mais do loop ( atC ) como antes.
[0] 0 :
TCt
A
t
CCCGGGGAG
atCTTAAGAG c
tataGAATTGGGCCCCTC
- TAGAATTCTC
TCt
T a
CCCGGGGAG
ttCTTAAGAG c
tataGAATTGGGCCCCTC -
AAGAATTCTC
[0] 1 :
TCg
A t
CCCGGGGCA
cgCTTAAGAG c
tataGAATTGGGCCCCGT -
GCGAATTCTC
GCg
T c
CCCGGGGCA
tgCTTAAGAG c
tataGAATTGGGCCCCGT -
ACGAATTCTC
[0,3 ] 0 :
TCt
A t
CCCGGGGAG
atCTTAAGAG c
aataGAATTGGGCCCCTC -
TAGAATTCTC
[0,3 ] 1 :
GCg
T c
CCCGGGGCA
tgCTTAAGAG c
aataGAATTGGGCCCCGT -
ACGAATTCTC
[1,3 ] 0 :
ACc
C t
CCCGGGGAG
caCTTAAGAG c
cgacGAATTGGGCCCCTC -
GTGAATTCTC
[1,3 ] 1 :
TCt
A t
CCCGGGGCA
atCTTAAGAG c
cgacGAATTGGGCCCCGT -
TAGAATTCTC
[2,3 ] 0 :
GCg
T c
CCCGGGGAG
tgCTTAAGAG c
gagtGAATTGGGCCCCTC -
ACGAATTCTC
[2,3 ] 1 :
ACc
C t
CCCGGGGCA
caCTTAAGAG c
gagtGAATTGGGCCCCGT -
GTGAATTCTC
[0,2 ] 0 :
TCt
T a
CCCGGGGAG
ttCTTAAGAG c
ataaGAATTGGGCCCCTC -
AAGAATTCTC
[0,2 ] 1 :
GCg
C t
CCCGGGGCA
cgCTTAAGAG c
ataaGAATTGGGCCCCGT -
GCGAATTCTC
[1,2 ] 0 :
TCt
T a
CCCGGGGAG
ttCTTAAGAG c
cagcGAATTGGGCCCCTC -
AAGAATTCTC
[1,2 ] 1 :
GCg
C t
CCCGGGGCA
cgCTTAAGAG c
cagcGAATTGGGCCCCGT -
GCGAATTCTC
Vamos supor que queremos transformar a string "010" numa cadeia de DNA indo pelo caminho: [0] , [0,2] , [1,2] , [0,2] .
Legenda:
- Molécula Inicial
- Saindo de [0] lendo 0.
- Saindo de [0,2] lendo 1.
- Saindo de [1,2] lendo 0.
GGGGAGATCatatCTTAACCCGGGGAGATCttatCTTAACCCGGGGCACGC
gtcgCTTAACCC
CCCCTCTAGtataGAATTGGGCCCCTCTAGataaGAATTGGGCCCCGTGCGcagcGAATTGGG