Detecção de Falhas
A primeira fase na tolerância a falhas é a detecção de erros. Como as falhas e avarias não podem ser detectadas diretamente, elas serão deduzidas a partir da detecção de erros no sistema. Assim, testes deverão ser executados para verificar suas ocorrências, a fim de dar-lhes o tratamento adequado. Deste modo, fica claro que a eficiência de um esquema de tolerância a falhas está baseada na sua eficiência em detectar erros. Idealmente, seria adequado que todos os erros fossem detectados. Entretanto, tal mecanismo exaustivo não seria viável na prática, fazendo com que seja necessário optar-se pelos erros a serem detectados. Devido à importância da detecção de erros, é necessário determinar como deve ser um teste ideal de erros. Existem algumas propriedades importantes que devem ser satisfeitas:
- Um teste ideal deve se basear somente na especificação do sistema, e não deve ser influenciado pelo seu design interno. O sistema deve ser considerado uma “caixa preta”, de forma que sua implementação seja ignorada.
- Um teste ideal deve ser completo e correto, isto é, todos os possíveis erros projetados a serem verificados devem ser detectados, e nenhum erro deve ser declarado quando não existente.
- O teste deve ser independente do sistema com respeito à suscetibilidade de falhas. Testes também podem falhar, e deseja-se que suas falhas não sejam relacionadas com falhas no sistema que está sendo verificado.
Apesar dos testes de caixa preta serem os mais importantes, existem situações onde um conhecimento prévio da implementação pode ser bastante útil na escolha dos testes a serem executados. Por exemplo, se todos os testes escolhidos para se verificar um determinado componente passam pelo mesmo fluxo no sistema, então todos eles estão testando praticamente a mesma coisa. Agora, se é conhecida a implementação, pode-se forçar situações para acompanhar o resultado de linhas de execução distintas.
Os testes de detecção de erro podem ocorrer de várias formas, dependendo do sistema e dos erros de interesse:
Testes de Replicação - Testes de Replicação são muito comuns e poderosos, podendo ser bem completos e implementados sem o conhecimento do funcionamento interno do sistema. Tal teste implica em replicar algum componente do sistema, e comparar ou votar resultados de diferentes componentes a fim de detectar erros. O tipo e a quantidade de replicações dependem da aplicação. Tal forma de teste é usada frequentemente em hardware, como por exemplo no TMR (Triple Modular Redundancy).
Testes de Temporização (Timing) - Se a especificação de um componente inclui restrições no tempo de resposta, então testes de Timing podem ser aplicados. Basicamente, tais testes realizam uma solicitação a algum componente e verificam se o tempo de resposta excede ou não a restrição imposta na especificação. Testes de Timing são usados tanto em hardware como em software. Em sistemas distribuídos, ele possui um papel importante, pois a falha de um nó é determinada pelo seu tempo de resposta a uma determinada solicitação.
Testes Estruturais e Semânticos - Em quaisquer dados, dois tipos gerais de testes são possíveis: testes de semântica e estruturais. Testes Semânticos tentam garantir se o valor é consistente com o resto do sistema. Testes Estruturais só consideram a informação e garantem que internamente a estrutura dos dados é como deveria ser. A forma mais comum de teste estrutural é a codificação, que é usada intensamente em hardware. Nela, bits extras são adicionados aos dados, de forma que é possível detectar se existe algum bit corrompido. Tal teste também pode ser usado em software, sendo aplicado às estruturas de dados.
Testes de Consistência - Utilizando o conhecimento de características inerentes ao sistema (invariantes), essa técnica consiste em realizar verificações em determinados pontos da computação, testando a consistência, ou seja, se os invariantes continuam sendo respeitados. Como exemplo de invariante podemos citar o caso de uma variável sempre conter um valor que pertença a um determinado intervalo. Pode-se testar se o valor dessa variável está no intervalo esperado. Outro exemplo é colocar assertions no meio do sistema, a fim de que inconsistências sejam detectadas.
Testes de Diagnóstico - Em Testes de Diagnóstico, um sistema usa alguns testes em seus componentes para verificar se ele está funcionando corretamente. A partir do conhecimento prévio de certos valores de entrada e de seus resultados de saída corretos, estes valores são aplicados ao componente e a saída é comparada com os resultados corretos.
Teste de Capacidade (Capability check) - Essa técnica consiste em verificar a capacidade do sistema antes da execução de alguma tarefa ou simplesmente utilizar o tempo livre do processador para verificar o funcionamento dos componentes do sistema. Pode-se verificar, por exemplo, se há quantidade de memória suficiente para a execução da tarefa, testar se não há falhas de comunicação entre os processadores de um multicomputador, dentre outros.
Testes de capacidade são mais frequentemente implementados por software, através de rotinas gerenciadas pelo sistema operacional, que são ativadas em intervalos em que o processador está livre, seu objetivo principal é a detecção de falhas. Porém ela se diferencia das demais pelo fato de não esperar que os erros ocorram e sim tentar descobrir se existem falhas no sistema para evitar que estas venham a afetar seu funcionamento.
Detecção de Erros
A seguir, são apresentadas algumas técnicas mais conhecidas de detecção de erros:
Duplicação
Consiste em simplesmente duplicar a informação original. Duplica o número de bits extra, e permite apenas a detecção de erros. Não é necessária nenhuma operação sobre a informação, sendo a simplicidade sua principal vantagem.
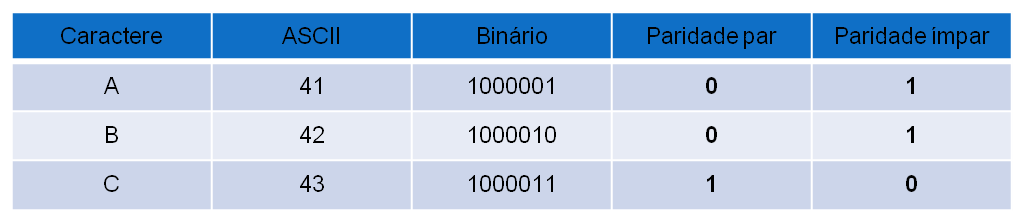
Paridade simples, paridade vertical ou TRC (Transverse Redundancy Check)
A cada caractere (8 bits) é adicionado um bit de paridade. De acordo com a escolha de paridade par ou ímpar, o bit de paridade deve tornar o número de 1’s par ou ímpar, respectivamente. Essa técnica é capaz de identificar apenas um número ímpar de bits trocados. A eficiência da utilização de bits nesse caso é de 8/(8+1) = 88,8%.
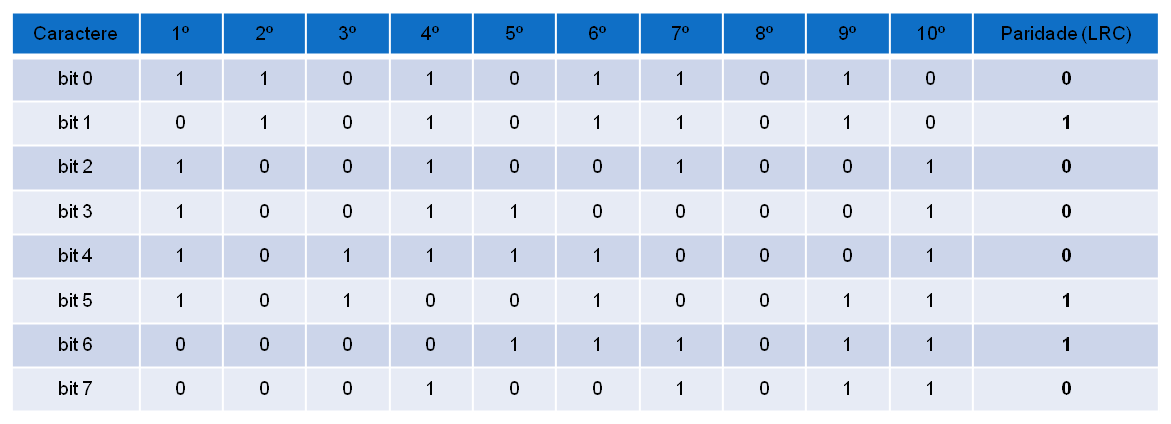
Paridade horizontal ou LRC (Logitudinal Redundancy Check)
Os caracteres são organizados em blocos e para cada bloco, calcula-se um caractere de checagem, que contém a paridade de cada ordem de bit dos caracteres. Essa técnica permite detectar mais de um erro em cada caractere, porém apenas 1 erro em bits de mesma ordem. A eficiência da utilização de bits dessa técnica depende do tamanho do bloco, calculada como (8*n)/(9*n+1), onde n é o número de caracteres em um bloco.
CRC (Cyclic Redundancy Check)
O CRC possui um algoritmo de cálculo mais complexo que os anteriores e é capaz de detectar erros de transmissão isolados ou em rajadas. Nessa técnica, cada bit da mensagem representa um coeficiente de um polinômio M(X), de forma que a ordem do polinômio seja inferior em 1 unidade ao número de bits da mensagem. Define-se o polinômio característico (gerador) G(X), de grau r, e desloca-se a mensagem de r posições para a esquerda (shift left). Quanto maior o grau do polinômio, maior a capacidade de detecção de erros. Os bits de maior e menor ordem devem obrigatoriamente ser iguais a 1. A mensagem é então dividida por G(X) (podendo ser realizada através de uma operação XOR (⊕)) e o resto da divisão é somado à mensagem deslocada, formando a mensagem composta T(X).
Na recepção, a mensagem recebida é novamente dividida por G(X). Se o resto da divisão for nulo, existe grande probabilidade da mensagem estar correta, caso contrário, existe um erro.
Checksum
Nessa técnica, os valores dos caracteres (bytes) da mensagem enviada são somados, e o resultado da operação módulo (resto na divisão por 256, no caso de um checksum de 8 bits) é o valor do checksum. Na recepção da mensagem, seus bytes são somados (com exceção do checksum), é feito um novo cálculo do checksum e comparado ao valor enviado na mensagem. Se os valores forem iguais, a probabilidade de existir um erro é muito baixa (só ocorreria se os bytes fossem alterados e ainda assim possuíssem o mesmo resto na divisão), caso contrário, existe modificação na mensagem enviada.
Confinamento e Avaliação de Danos
Se o sistema não for monitorado constantemente, haverá um intervalo entre a falha e a deteccção do erro. Desta maneira, este erro pode se propagar para outras partes do sistema. Por isso, antes de executar medidas corretivas, é necessário determinar exatamente os limites da corrupção, ou seja, as partes do estado que estão corrompidas. Erros se espalham em um sistema através da comunicação entre componentes. Por isso, para avaliar o estrago após a detecção de um erro, o fluxo da informação entre diferentes componentes deve ser examinado. Algumas suposições devem ser feitas sobre a origem e o momento de geração do erro. O objetivo é encontrar as barreiras no estado, além das quais nenhuma troca de informação tenha sido feita. As barreiras podem ser encontradas dinamicamente, gravando-se e examinando-se o fluxo da informação. Por ser complexo, uma melhor maneira é projetar o sistema tal que “firewalls” são estaticamente incorporados no sistema, de forma a garantir que nenhuma informação se espalhe para além deles.
Tratamento de Falhas
Nas fases anteriores, o foco era sempre o erro. Se ele foi gerado por uma falha transiente, ela não precisa ser tratada, pois já desapareceu. Entretanto, se ela é permanente, então ainda está presente após a recuperação. Desta maneira, se o sistema for reinicializado, o erro ocorrerá novamente. Para evitar este comportamento, o componente defeituoso deve ser identificado e não mais utilizado. Esta fase possui duas sub-fases:
- Localização da Falha - Nesta fase, o componente defeituoso precisa ser identificado. Se não for possível sua localização, não será possível reparar o sistema para que o erro não ocorra novamente. Tipicamente, após detectar o erro, o componente defeituoso é identificado como sendo aquele mais próximo da origem do erro.
- Reparo do Sistema - Nesta fase, o sistema é reparado para que o componente defeituoso não seja usado novamente. Deve ser notado que a manutenção é feita on-line, sem intervenção manual. O reparo é feito por um sistema de reconfiguração dinâmica, tal que a redundância presente no sistema distribuído é usada para substituir o componente defeituoso.
